Credmark Data ETL
Part III
Momin Ahmad
2021/12/20

In the last two posts, we explored our thesis as a project and the significance of our upcoming platform (Which is now live! Check it out).
We now take a look at the data ETL portion of our platform. This post will illustrate the following points:
- Why we chose to build our own data ETL,
- The types of data we are currently working with,
- Our competitive landscape and how we differ,
- How we are approaching the decentralization process of our ETL,
- How we plan on delivering data to our growing community of engineers, scientists and developers.
Why Credmark is building out its own data ETL
Credmark is a DAO and intends to service the DAO-to-DAO business model with data available in a permission-less manner.
At the core, we are a data company; so relying on 3rd party data is risky and unreliable. Throughput will be high on our platform, and our past experience working with 3rd parties has led to less than desirable results. If our data provider were to go down and we are unable to address the issue, we lose credibility as a reliable source of data. Using 3rd parties for data leads to issues on throttling, security risks, and deploying additional resources dedicated to managing that external relationship.
Additionally, situations like disaster recoveries will be hard to address when direct access or the management of the data infrastructure is unavailable.
There is also a matter of methodologies and by extension, scalability, when working with 3rd parties. In order to really trust 3rd parties for data that fuels the core of your business; you need a solution that has business viability, high uptime, SLA’s, extensive documentation, and high throughput. We’ve found all of this to be lacking with the current providers on the scene.
Blockchain data is public, so it was rational to extract the data ourselves.
We have been working hard to build our data ETL. However, it’s not ready for public use just yet. To allow for us to work on a few projects in parallel, we’ve leveraged The Graph for the current iteration of our platform. In the next few months, we’ll be swapping out the data backend for our own dataset derived from on-chain data. Even when our initial dataset is complete, we’ll still leverage other data providers for research that fuels the risk library content.
Credmark’s Orders of Data
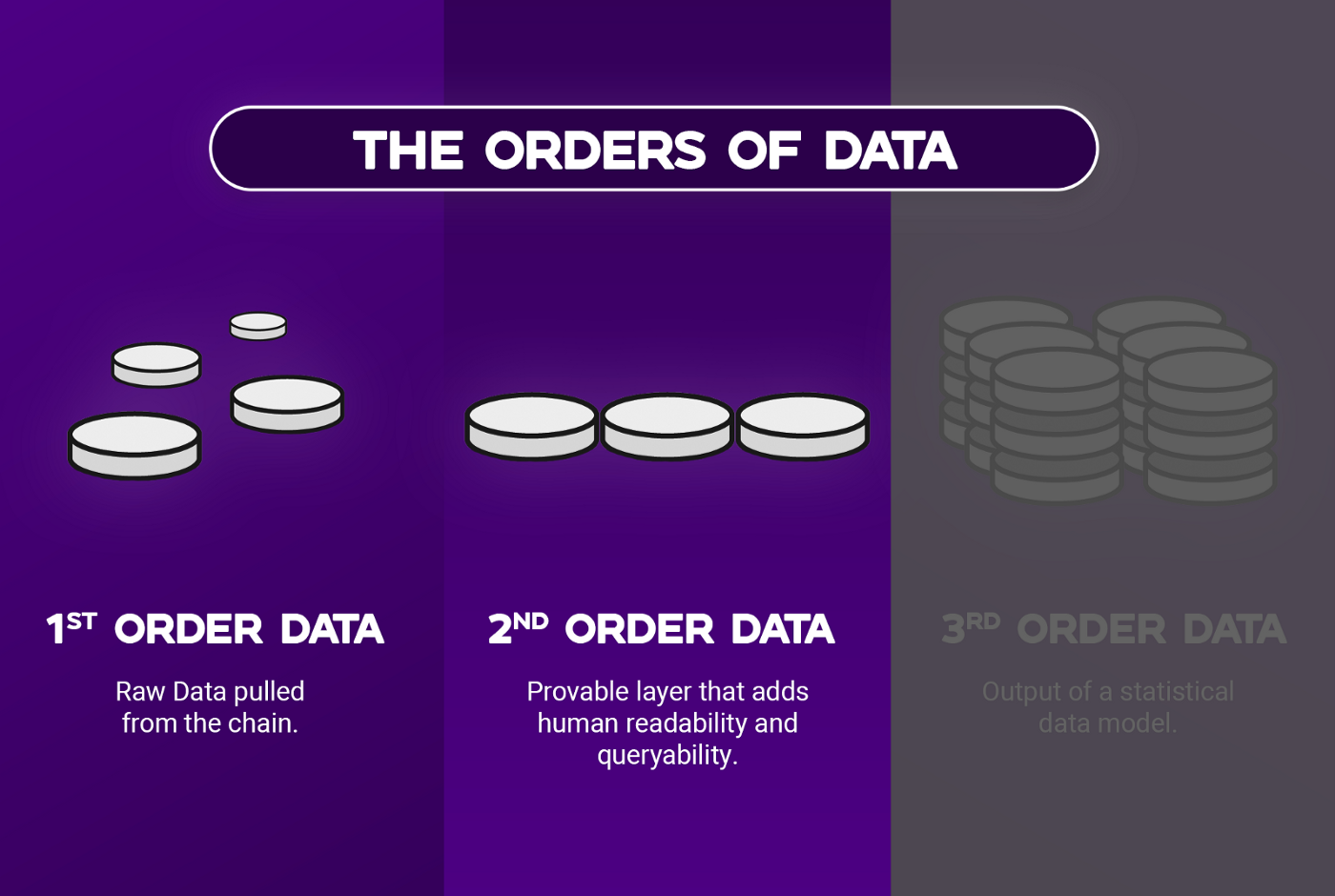
We used open source tooling, Ethereum ETL, to export the blockchain into a data lake. We wanted to avoid using SQL based databases since those do not scale well, so we chose to export it into an AWS data lake.
1st order data is raw so it’s either in number or hex values which makes it unreadable for most people.

Leveraging the Athena service, we can then convert this data into queryable data. Still raw, but slightly more organized.
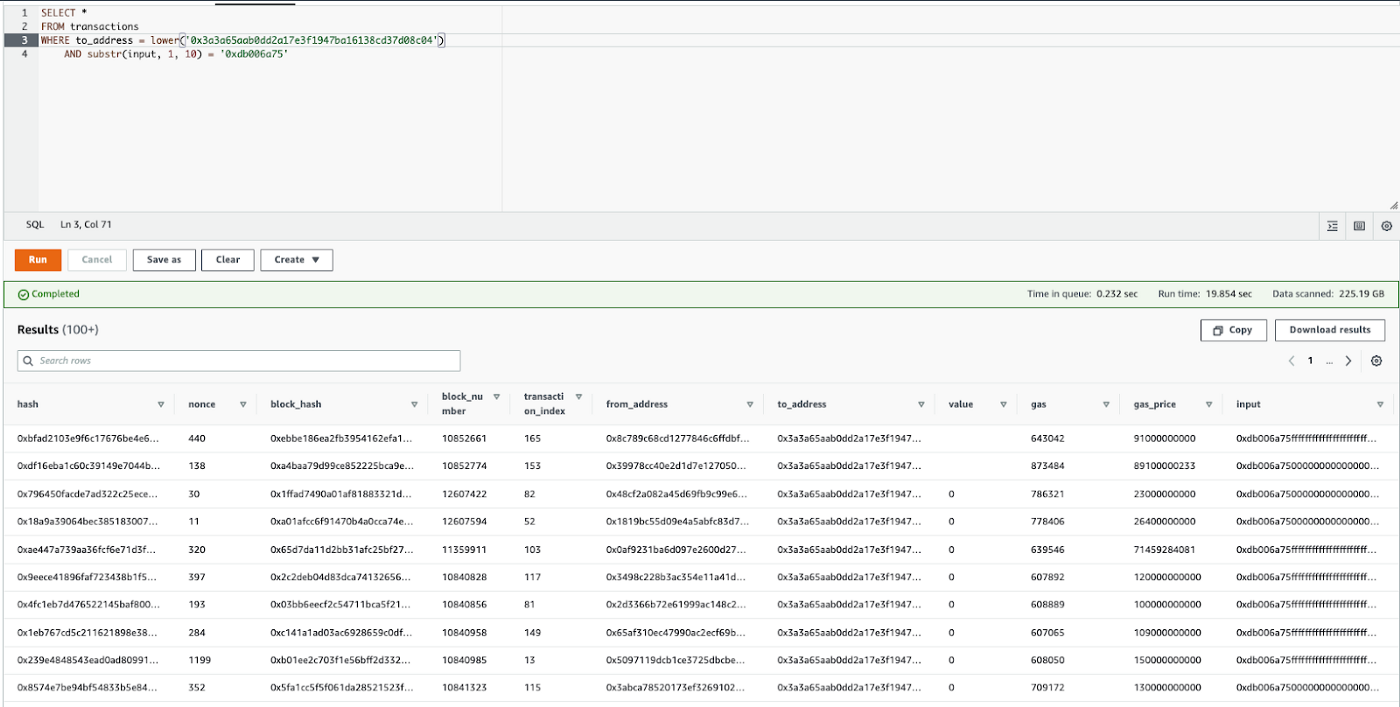
Our 2nd order data is basically 1st order data combined with ABIs from smart contracts so it is human readable and interpretable.
An ABI is essentially a filter that can be applied onto raw data to make sense of the data. It allows us to understand what each function does in order to add context to each transaction.
Competitive Landscape
Other organizations in the same field started out with Postgres, whereas we chose to use Apache Parquet. It provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk.
Postgres requires more centralized maintenance in regards to storage and computing power; and is difficult to migrate. Normally, you’d have a DB admin to maintain, optimize, and migrate relational databases. Now, centralized providers like AWS exist and offer managed relational databases. However, this still requires some maintenance and still has the difficulty of: moving data around, adding and removing rows and columns.
To Credmark, this does not sound like a properly structured decentralized infrastructure. We chose to start by using tools that are server-less and not hosted on a single (or cluster) of managed servers. This choice allows us to automatically scale our storage and throughput to our needs.
Credmark’s data infrastructure
We’re not fully decentralized yet, but we designed our infrastructure to be easily migratable from the very start. That is why we started with tools that are server-less and aren’t required to be in a specific data storage.
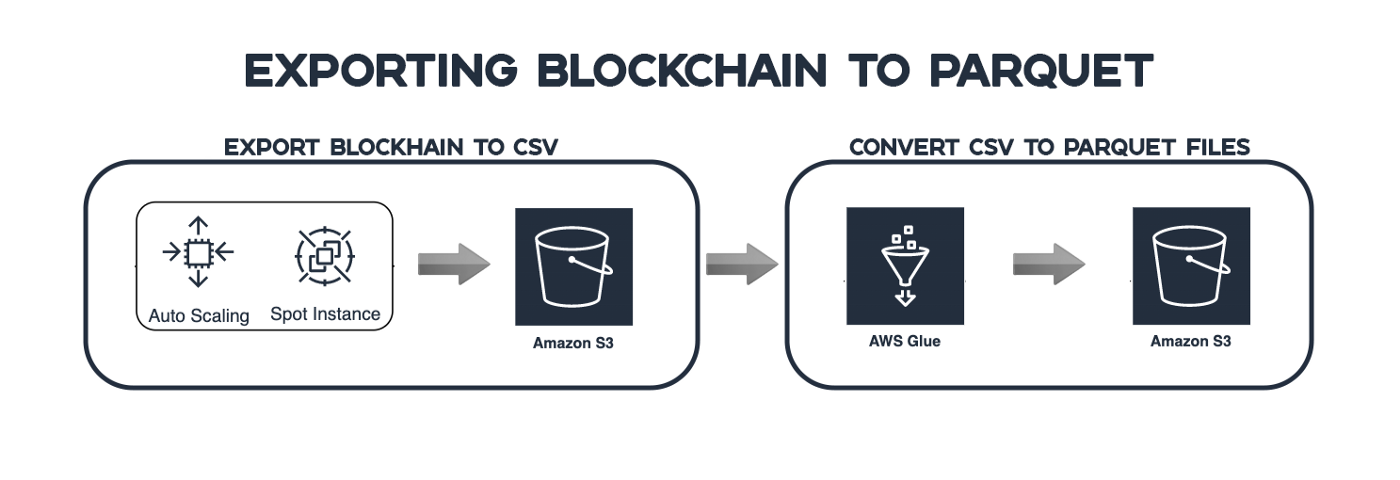
For the blockchain export, we are using existing Amazon services so we don’t have to manage servers ourselves. We are leveraging auto-scaling groups with EC2 instances in order to export data from Ethereum ETL into Amazon S3 (simple storage) using the AWS Data Pipeline.
The data is first stored as CSV data. We need to convert this to something more queryable. CSV’s are not efficient when looking for specific data. We can leverage AWS Glue in order to convert the data from CSV into Apache Parquet files which are also stored on the S3 storage buckets. Parquet files are in a columnar format which allows us to query specific columns as opposed to the whole file making querying faster, cheaper and more sustainable.
In the future, we want to leverage containers for people to help with the computation workload. These would be Credmark ‘nodes’.
With Apache Parquet, we can store it anywhere that we can save files. Later, we can shift to other data stores like blockchainDB or IPFS.
We are a Big Data company that wants to decentralize, and we want to share our experiences and discoveries along the way.
What developers and engineers can expect from the Credmark platform
On the road to becoming a DAO; we are continuously encouraging our community to voice their opinions, their skill sets, and their ideas so we can build the platform to fulfill our community’s needs. To that end, we’re also working with a team of engineers and analysts to see what they like to work with and how they like to process this kind of information.
Currently, our platform has graphs and charts for individuals who are concerned about data, but don’t know how to use data.
We are also in the process of building out API access for developers and engineers who want to consume the data that is currently viewable in the web platform.
In addition, we will have various data formats for data analysts/scientists to consume; but we need your input to make sure we’re doing it right! If you are a data enthusiast or developer/engineer, please share with us how you work and what you like to use.

Sign up for our newsletter for the latest product updates, partnerships, and more.